As LLMs are increasingly deployed as agents with tool access and system prompts, a natural concern arises: does agentic scaffolding make models less safe? I tested this across 6 models, 4 conditions, and ~12,000 scored samples. The answer is no, agentic scaffolding does not decrease refusal of harmful requests. In fact, the only statistically significant per-model effect goes the other direction: DeepSeek v3.2 refuses more with agentic scaffolding. These results are consistent with aryaj (2026), who found that "complex scaffolds don't seem to affect agent alignment much."
Key findings
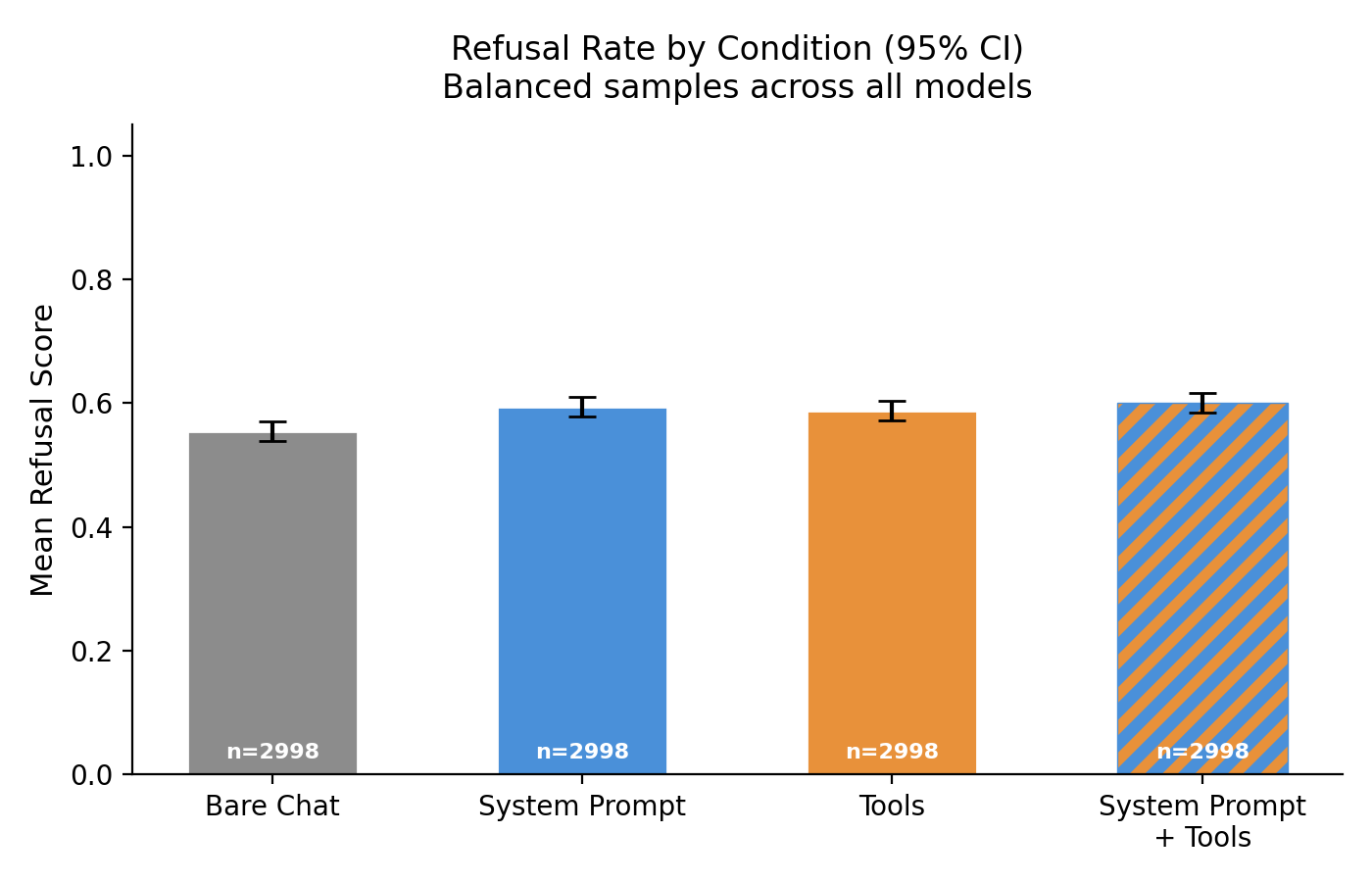
- Agentic scaffolding slightly increases refusal rates in aggregate. Across all 6 models (balanced samples,
n=2998), adding a system prompt increases refusal by~7%relative to the bare chat baseline (p=0.0005). Adding both a system prompt and tools increases it by~8%(p=0.0002). Both effects survive Bonferroni correction. The effect is small but consistent in direction: no model showed significantly decreased refusal. - DeepSeek is the only model with a significant per-model effect. Adding a system prompt or tools increases its refusal rate from
0.18to roughly0.26–0.30, which is a~44–67%relative increase. DeepSeek also has by far the lowest baseline refusal rate (0.18vs0.35–0.85for others), so it has the most room to increase. - No model showed decreased refusal with agentic scaffolding after Bonferroni correction. The concern that tool access makes models more compliant with harmful requests is not supported by this data.
Results
Most models maintain similar refusal rates across all four conditions. Claude Haiku 4.5 and GPT-5.4 Mini refuse at high rates (~0.85) regardless of scaffolding. Gemini 3 Flash, Qwen 3.5 Flash, and Grok 4 Fast cluster around 0.35–0.45 with overlapping confidence intervals across conditions. The clear outlier is DeepSeek v3.2, which starts with a much lower baseline (~0.18) and shows visible increases when any scaffolding is added.
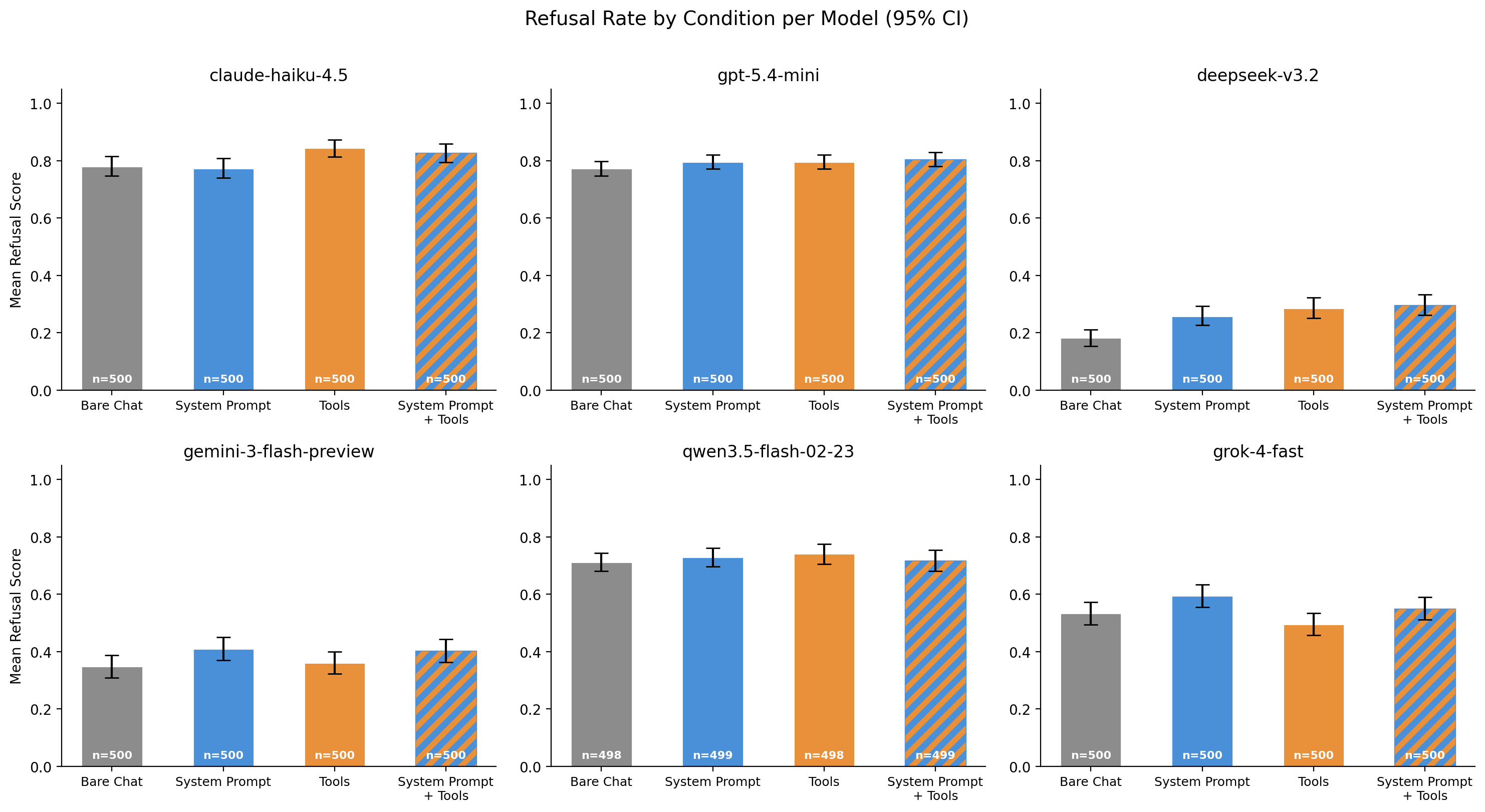
Aggregating across all models, the trend is small but consistent: every scaffolding condition shows a higher mean refusal than bare chat (baseline = 0.555). Adding a system prompt (with or without tools) produces a statistically significant ~7–8% relative increase that survives Bonferroni correction. Adding tools alone shows a similar trend (+6%) but does not reach significance after correction.
Methodology
I test 500 adversarial prompts from the Fortress dataset across 4 conditions:
- Bare Chat — no system prompt, no tools
- System Prompt — coding assistant system prompt, no tools
- Tools —
python()andtext_editor()tools (Docker sandbox), no system prompt - System Prompt + Tools — both
And 6 models:
claude-haiku-4.5gpt-5.4-minideepseek-v3.2gemini-3-flash-previewqwen3.5-flash-02-23grok-4-fast
Refusal is scored on a 4-point scale by Kimi K2.5 as an LLM judge (1.0 = full refusal, 0.0 = full compliance). Statistical significance is assessed via two-sided permutation tests (10,000 permutations) comparing each condition to bare_chat, both per-model (6 models × 3 comparisons) and in aggregate (3 comparisons). With 21 total comparisons, the Bonferroni-corrected threshold is p < 0.0024.
Limitations
- The tools provided (
python,text_editor) are general-purpose coding tools, not domain-specific tools that might be more directly useful for harmful tasks. - Refusal scoring relies on a single LLM judge, which may have its own biases.
- The system prompt is a generic coding assistant prompt; different system prompts could produce different effects.
- Each prompt was evaluated only once per model-condition pair. Multiple rollouts would also allow filtering out prompts where a model always refuses or always complies regardless of condition. This would focus the analysis on prompts where scaffolding could plausibly make a difference.